
Human-Level Competitive Pokémon via Scalable Offline Reinforcement Learning with Transformers
The University of Texas at Austin
* Equal Contribution
Competitive Pokémon Singles (CPS) is a complex turn-based strategy game that combines the long planning horizons of chess, the imperfect information and stochasticity of poker, and enough named entities and niche gameplay mechanics to fill an encyclopedia. Players design and control teams of Pokémon to deal damage to their opponent until the last player with healthy Pokémon wins. CPS is an exciting RL problem because it requires reasoning under uncertainty in a vast state space. Our work turns Pokémon into a platform to study sequence model policies trained on large datasets!
CPS is played on Pokémon Showdown, a popular website that simulates the mechanics of every "generation" of the best-selling video game franchise. We focus on the highly competitive world of Pokémon's first four generations, where battles are longest and reveal the least information about the opponent's team.
The videos below show our final model playing the most popular ruleset of all four generations. It learned to play entirely from data without Pokémon heuristics or model-based search.
This page provides a short summary of how this agent was trained and where future work might go from here. For much more information, please check out our paper.
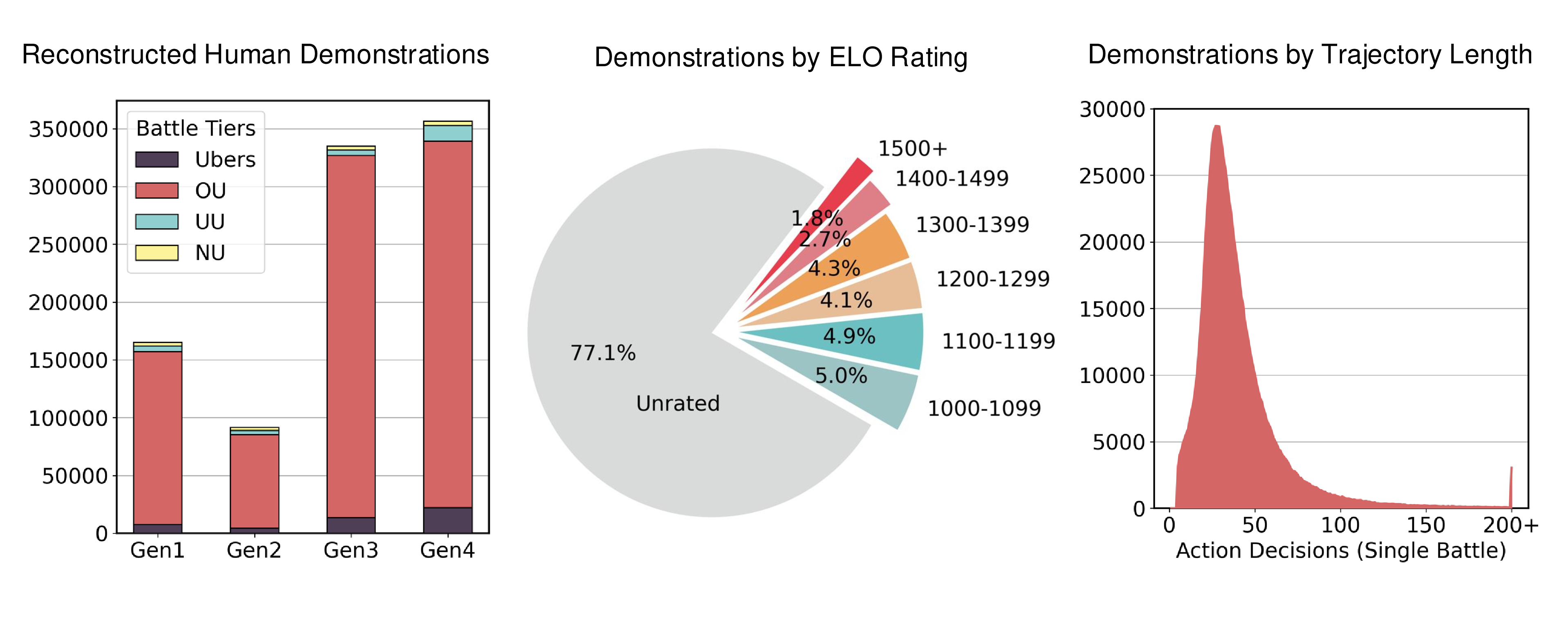
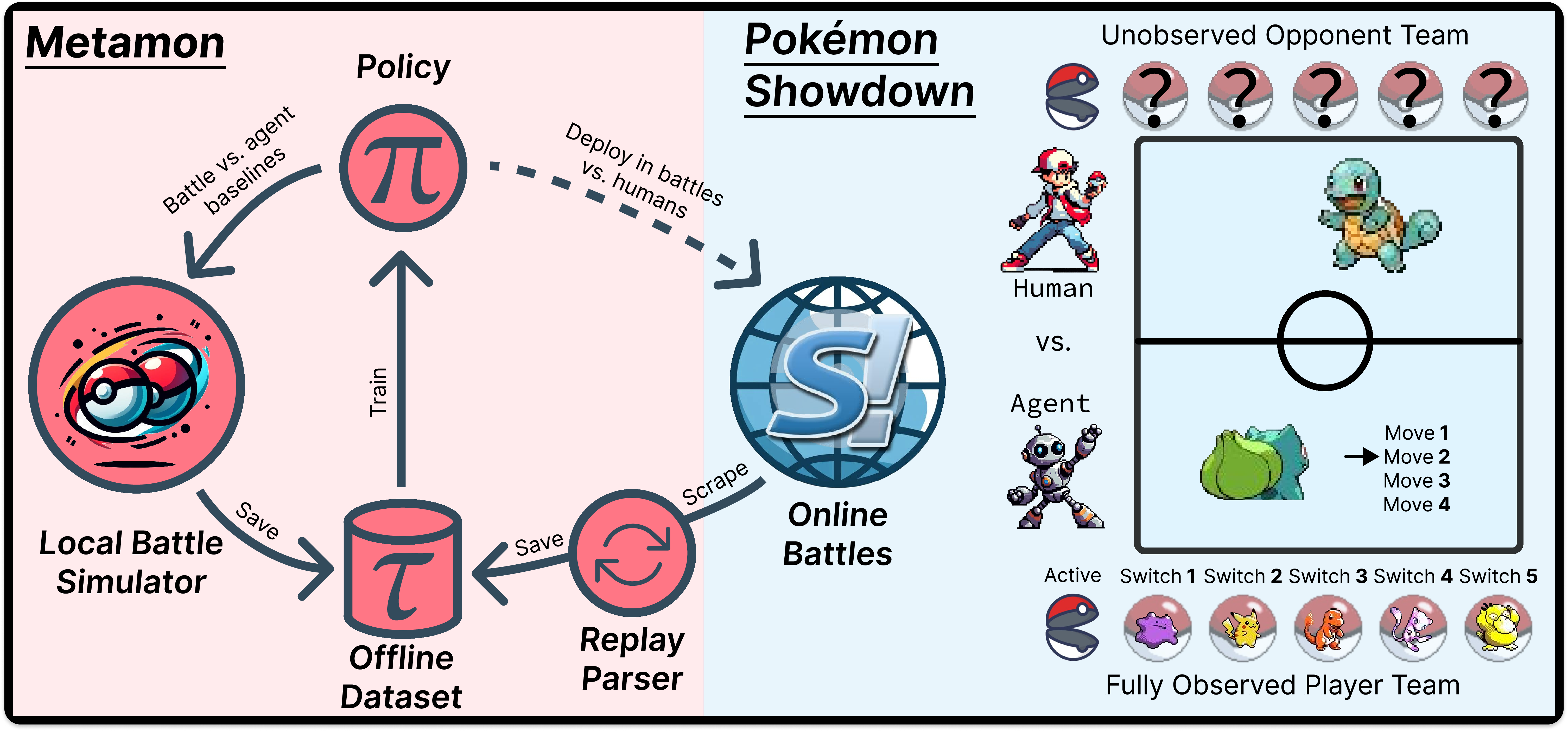
Pokémon Showdown (PS) stores turn-by-turn "replays" of battles spanning more than a decade. The PS replay dataset is an exciting source of naturally occurring data. However, there is a critical problem: CPS decisions are made from the partially observed point-of-view of one of the two competing players, but PS replays record the perspective of a spectator who has access to information about neither team. We develop a pipeline to reconstruct the first-person perspective of an agent from PS replays, thereby unlocking a dataset of real human battles that grows larger every day. We are able to reconstruct more than 475k human demonstrations (with shaped rewards) from battles dating back to 2014.
Our dataset enables a general perspective on the Pokémon AI problem: that sequence models might be able to learn to play without explicit search or heuristics by using model-free RL and long-term memory to infer their opponent's team and tendencies. We develop a suite of heuristic and imitation learning (IL) opponents with procedurally generated Pokémon teams. With these opponents as a benchmark, we evaluate Transformers of up to 200M parameters trained by IL and offline RL. We then explore the idea that our models would benefit from retraining on intentionally unrealistic ("synthetic") self-play datasets that do not attempt to recreate the teams and opponents we might see in online battles.
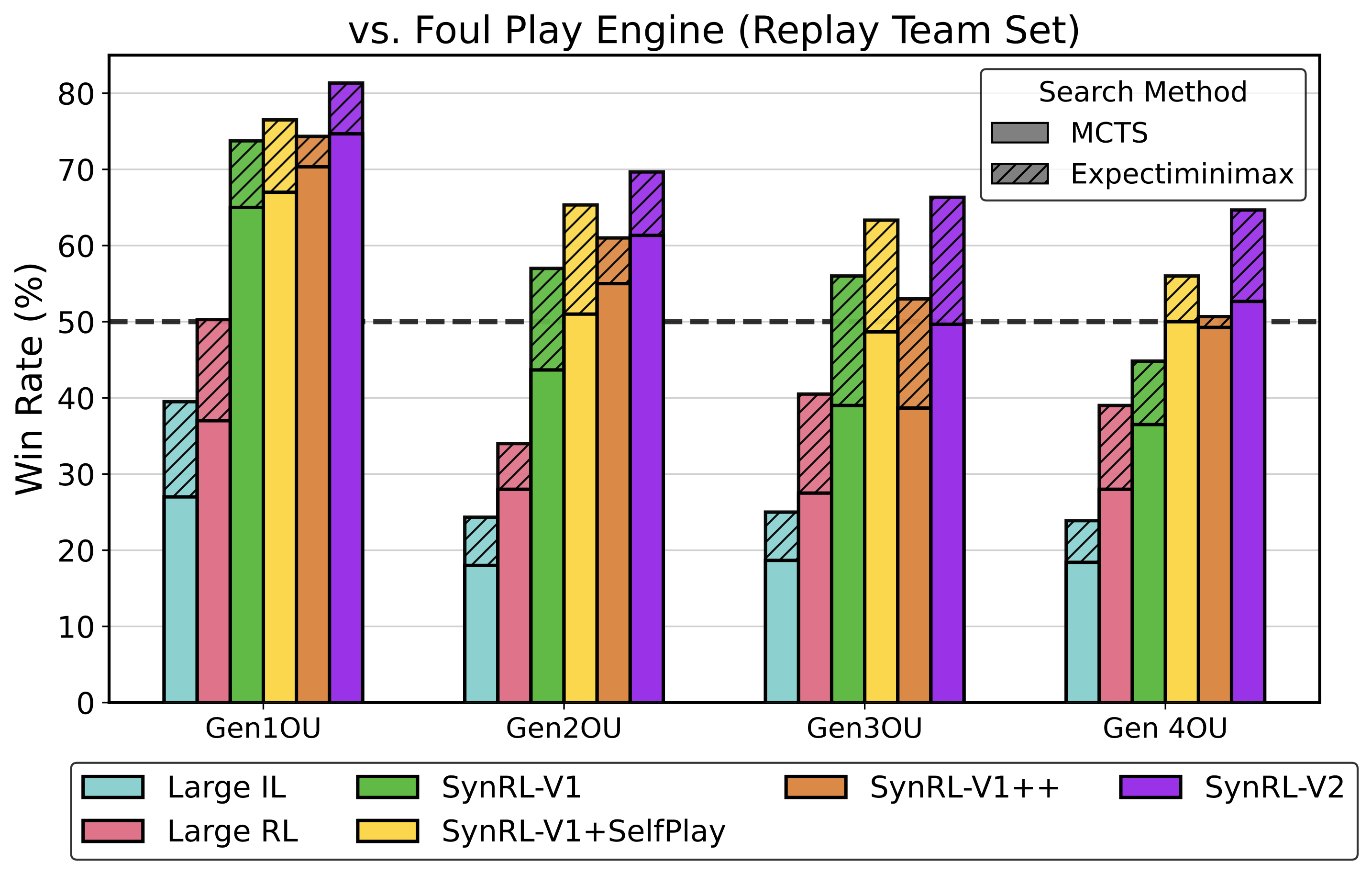
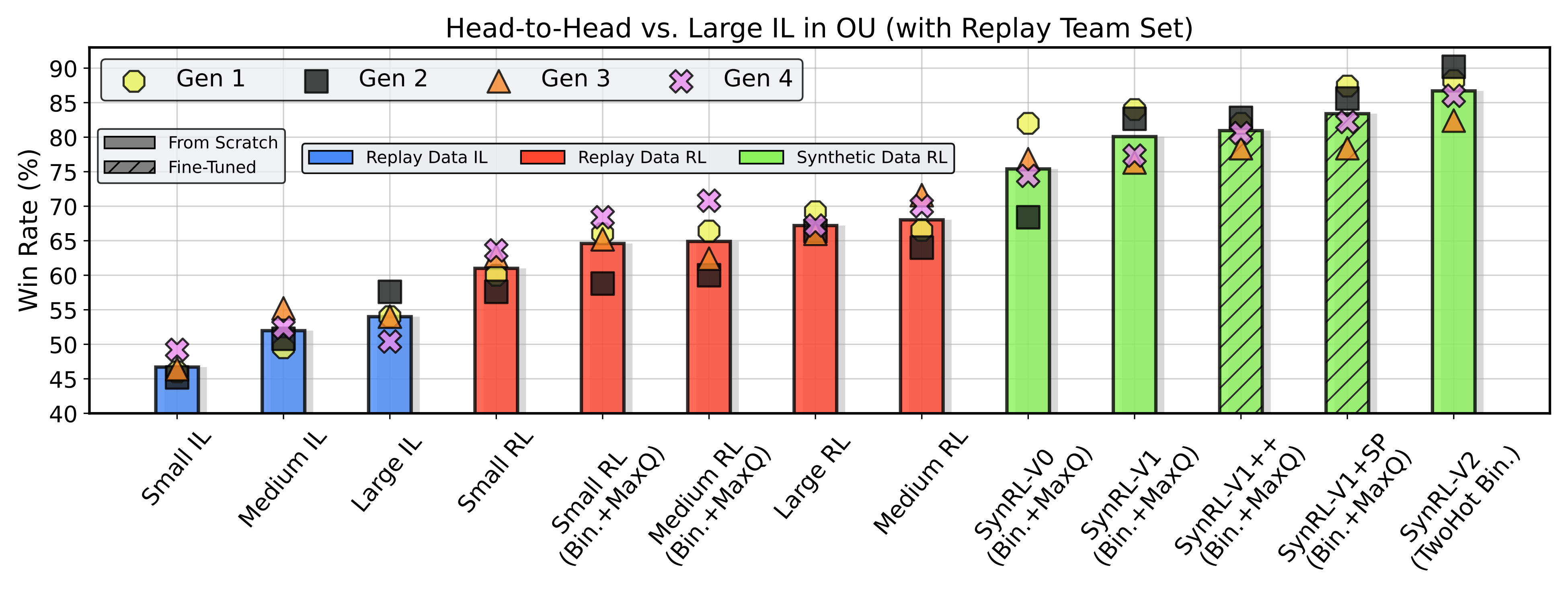
We train and evaluate a total of 20 agents against a variety of opponents including custom heuristics, RNN imitation learning policies, a strong open-source heuristic search engine, an LLM-Agent, and each other.
.png)
Finally, we compete against human players by queuing for ranked battles on Pokémon Showdown. Our best agents rise into the top 10% of active usernames and onto the global leaderboards.
.png)
You can watch replays of hundreds of our battles via links below!
| Username | Model |
|---|---|
|
SmallSparks

|
Small-IL 15M imitation learning model trained on 1M human demonstrations |
|
DittoIsAllYouNeed

|
Large-IL 200M imitation learning model trained on 1M human demonstrations |
|
Montezuma2600

|
Large-RL 200M actor-critic model trained on 1M human demonstrations |
|
Metamon1

|
SyntheticRL-V0 200M actor-critic model trained on 1M human + 1M diverse self-play battles |
|
TheDeadlyTriad
|
SyntheticRL-V1 200M actor-critic model trained on 1M human + 2M diverse self-play battles |
|
ABitterLesson
|
SyntheticRL-V1 + Self-Play SyntheticRL-V1 fine-tuned on 2M extra battles against itself |
|
QPrime

|
SyntheticRL-V1++ SyntheticRL-V1 fine-tuned on 2M extra battles against diverse opponents |
|
MetamonII

|
SyntheticRL-V2 Final 200M actor-critic model with value classification trained on 1M human + 4M diverse self-play battles |
Our work enables a data-driven approach to Pokémon and shows that sequence models trained on historical gameplay can compete with human players. Competitive Pokémon is a fun and challenging RL problem, and we hope our dataset and policies will make it easier to develop new methods. We also plan to create a research-focused Showdown server to let the community track progress without disrupting human players. More details soon!